
AI Mac設定 Windows設定 WordPress おすすめアプリ おすすめガジェット お得情報 コピペで使える ブログ運営 ミニマリズム 中学生でもわかるIT 健康 問題解決 自動化 読書 転職先選び




前回の記事でPLAUD NOTE ProのAI要約の精度がいまいちだと書いた。そこで私が構築したのが、PLAUD NOTEの文字起こしデータをZapier経由でGitHubに自動保存し、ローカルのAIツールで解析するパイプラインだ。これが想像以上に快適だったので、具体的な仕組みと構築方法を紹介する。
あわせて読みたい


PLAUD NOTE Proを3ヶ月使った正直な感想【AIボイスレコーダーの実力】
AIボイスレコーダー「PLAUD NOTE Pro」を購入して3ヶ月が経った。会議の議事録作成、日々の打ち合わせの記録、電話の録音。あらゆる場面で使い倒してきた結果、見えてき…
目次
なぜPLAUD NOTE標準のAI要約では足りないのか
PLAUD NOTEのクラウドには、録音データから要約や議事録を自動生成する機能がある。ワンクリックで結果が出てくるので手軽ではあるのだが、前回の記事でも触れた通り、精度に難がある。
特に困るのが「肝心なところが抜ける」問題だ。会議の雑談部分はしっかり拾っているのに、重要な決定事項や具体的な数字が要約から消えているケースが何度もあった。
原因はおそらく、クラウド側がスピード重視でAIモデルを動かしているからだろう。シンキングモード(深い推論を行うモード)を使えばもっと精度は上がるはずだが、クラウドサービスとしてはコストとレスポンスのバランスがある。そこを責めても仕方ない。
であれば、文字起こしデータだけもらって、解析は自分の環境でやればいい。そう考えて構築したのが今回のパイプラインだ。

システム全体像:4ステップで完全自動化
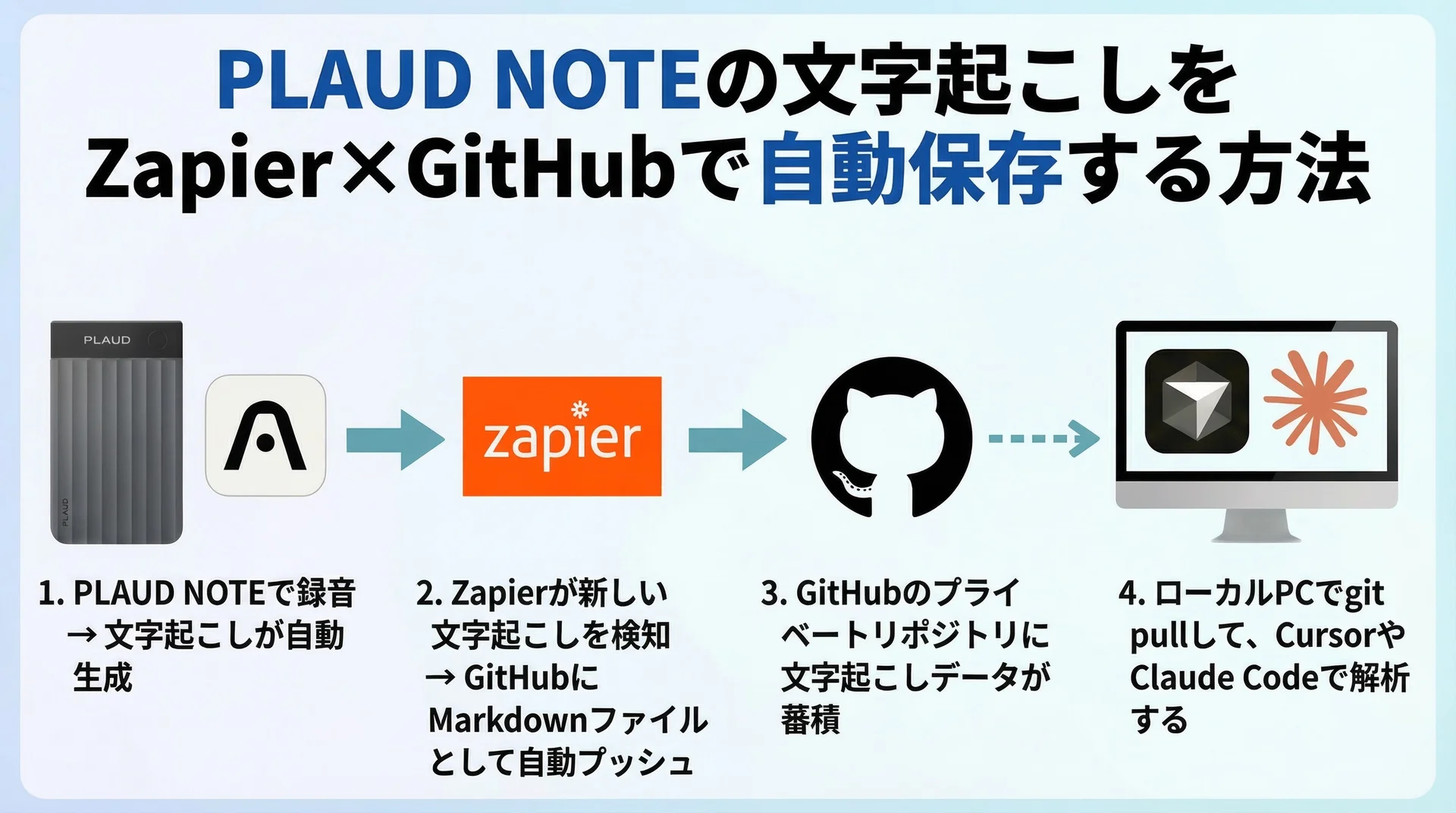
パイプラインの全体像はシンプルだ。
- PLAUD NOTEで録音 → 文字起こしが自動生成される
- Zapierが新しい文字起こしを検知 → GitHubにMarkdownファイルとして自動プッシュ
- GitHubのプライベートリポジトリに文字起こしデータが蓄積される
- ローカルPCでgit pullして、CursorやClaude Codeで解析する
一度セットアップしてしまえば、1〜3は完全に自動で回る。自分がやることはローカルでpullして、AIに「この会議の議事録を作って」と指示するだけだ。
Zapierの設定:PLAUD NOTE → GitHubの橋渡し
ここが構築の核となる部分だ。Zapierで「PLAUD NOTEに新しい文字起こしが生成されたら、GitHubにファイルを作成する」というZapを組む。
トリガー:PLAUD NOTEの新規文字起こし
ZapierのトリガーにPLAUD NOTEを設定し、新規の文字起こしデータが生成されたタイミングで発火させる。PLAUD NOTEはZapier連携に対応しているので、アカウントを接続するだけで設定できる。
アクション:GitHub Create File
アクション側はGitHubの「Create File」を使う。設定するフィールドは以下の通りだ。
リポジトリ: 事前に作成しておいたプライベートリポジトリを選択する。公開リポジトリにすると文字起こしデータが世界中に公開されてしまうので、必ずプライベートにすること。
ブランチ: mainを指定する。
ファイルパス: ここが少し工夫が必要だ。Zapierの「Formatter」ステップを使って、日時とタイトルを組み合わせたファイル名を動的に生成する。
具体的には、PLAUD NOTEから取得した作成日時をFormatterでYYYYMMDD_HHmm形式に変換し、タイトルと連結してraw_data/20260219_1430_ミーティングメモ.mdのようなパスを組み立てる。ファイル名にスペースを入れないのがポイントだ。
ファイルコンテンツ: PLAUD NOTEの文字起こし本文(Transcript)をそのままマッピングする。
コミットメッセージ: feat(raw): 20260219 1430 ミーティングメモのように、日時とタイトルを含めておくとgit logで探しやすくなる。
ローカルへの同期:シェルスクリプト一発
GitHubにデータが溜まったら、ローカルに持ってくる。といっても、やることはgit pullだけだ。
AIツールで解析:ここからが本番
ローカルに文字起こしデータが届いたら、いよいよAIツールの出番だ。私はCursorやClaude Codeを使っている。
例えば会議の文字起こしファイルを開いて、「この会議の議事録を作成して。決定事項、TODO、次回までの宿題を整理して」と指示するだけで、PLAUD NOTE標準のAI要約とは比べ物にならない精度の議事録が出来上がる。
シンキングモードを持つ最新のAIモデルは、文脈を深く理解した上で要約してくれる。「誰が何を言ったか」「何が決まって何が保留になったか」「次のアクションは誰が担当か」といった、実務で本当に必要な情報を正確に抽出できる。
議事録以外にも使い道は幅広い。1on1の内容をまとめてフィードバックシートを作ったり、商談の会話から相手のニーズを分析したり、複数回の会議を横断して進捗をトラッキングしたりと、生の文字起こしデータがあるからこそできることは多い。
最大のメリットは「ローカルのMarkdown」であること
このパイプラインの真の価値は、文字起こしデータがローカルのMarkdownファイルとして手元に存在することだ。
PLAUD NOTEのクラウドにもデータは残る。しかし、クラウドにしかデータがない場合、そのサービスの中でしかデータを扱えない。PLAUD NOTEのAI要約がいまいちでも、他のAIに食わせることができない。データはあるのに、活用方法がPLAUD NOTEの機能に縛られてしまう。これは非常にもったいない。
ローカルにMarkdownファイルとして保存されていれば、話はまったく変わる。Cursor、Claude Code、ChatGPT、Gemini、何でもいい。その時点で最も優れたAIツールに文字起こしデータを渡せる。AIの世界は進化が異常に速いので、半年後にはもっと高精度なツールが出ているかもしれない。ローカルにデータがあれば、いつでも最新のツールで再解析できるのだ。
さらにGitHubで管理しているので、ネットワーク上にもデータが存在する。別のマシンからでもcloneすればすぐに使える。ローカルとクラウドの両方にデータがある状態を、自分のコントロール下で維持できるのが強い。
この考え方は、以前紹介したObsidianによる知識ベース構築とまったく同じだ。Obsidianの最大の強みは、ノートがローカルのMarkdownファイルとして保存されること。NotionやEvernoteのようにサービス側にデータを預けるのではなく、自分の手元にプレーンテキストとして持つ。だからAIツールで一括解析もできるし、grepで横断検索もできるし、サービスが終了しても一切困らない。
PLAUD NOTEの文字起こしデータも、同じ思想でローカルに持ってくる。録音データという資産を、特定のサービスに閉じ込めず、オープンなフォーマットで自分の手元に置く。これが、このパイプラインの本質的な価値だ。
あわせて読みたい

Obsidianで作る第二の脳!ローカル管理の知識ベース構築法
あなたは今、どのノートアプリを使っているだろうか? Evernote、Notion、OneNote…多くのクラウドノートアプリがあるが、何かしっくりこないと感じたことはないだろうか…
まとめ
PLAUD NOTEの文字起こしデータをZapier経由でGitHubに自動保存し、ローカルのAIツールで解析するパイプラインを紹介した。構築に必要なのはZapierアカウント、GitHubのプライベートリポジトリ、そして数行のシェルスクリプトだけ。一度セットアップすれば、あとは全自動で文字起こしデータが手元に届く。PLAUD NOTE標準のAI要約に物足りなさを感じている人は、ぜひ試してみてほしい。










